RoomPlan
The paper about RoomPlan is fascinating to read. The result may seem simple, but it is the output of carefully designed and optimized steps that open the door for improved semantic understanding of physical contexts.




RoomPlan uses camera and LiDAR to make a 3D floor plan of a room (including dimensions and types of furniture).
The system is made up of two parts:
- 3D room layout estimation (RLE)
- 3D object-detection pipeline (3DOD)
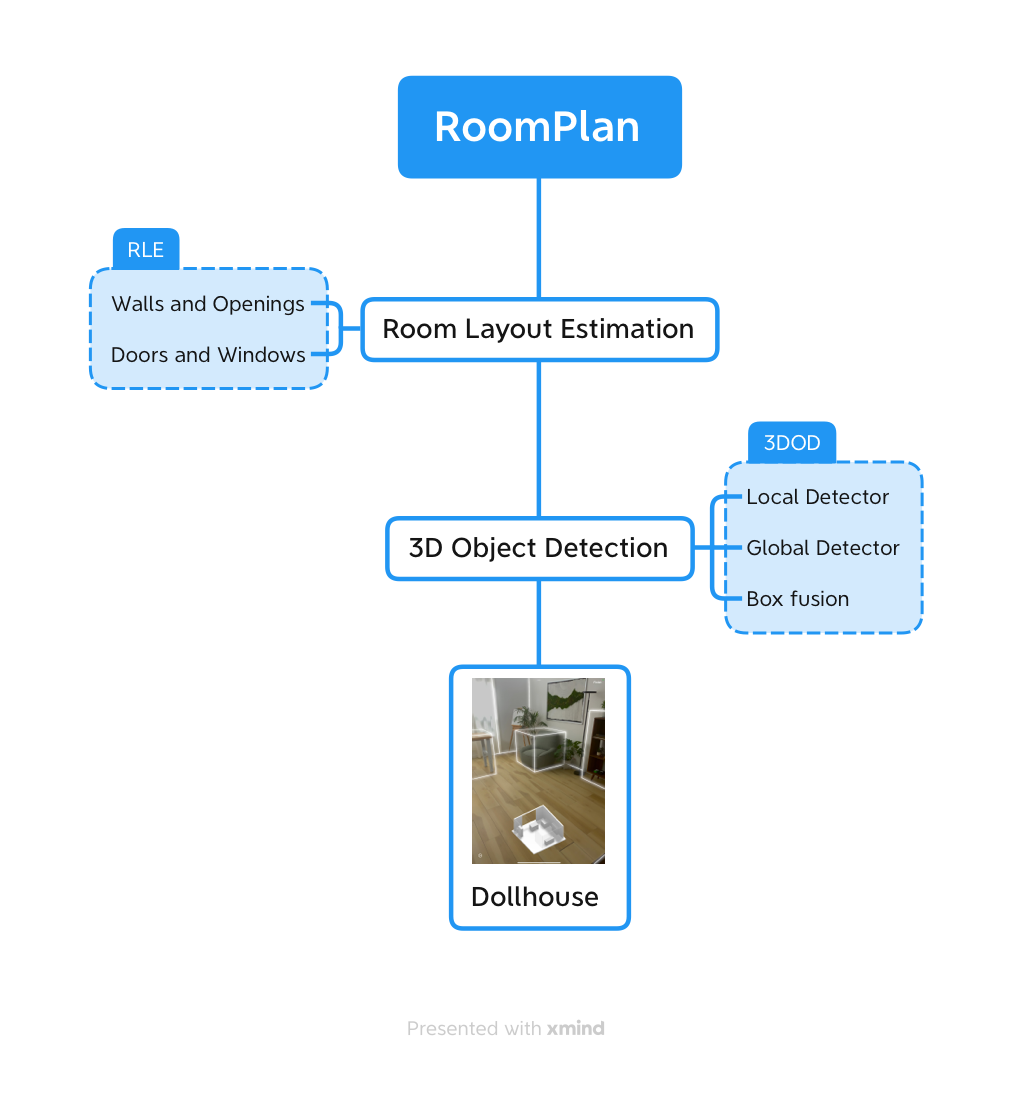
Room Layout Estimation
RoomPlan first finds the walls and openings, and then the result is used to figure out if the openings are doors or windows.


3D Object Detection
3DOD goes through a three-step process that first recognizes and categorizes objects locally, then globally for more information, and finally uses a box fusion process to create the dollhouse result, or 3D representation of the whole room.
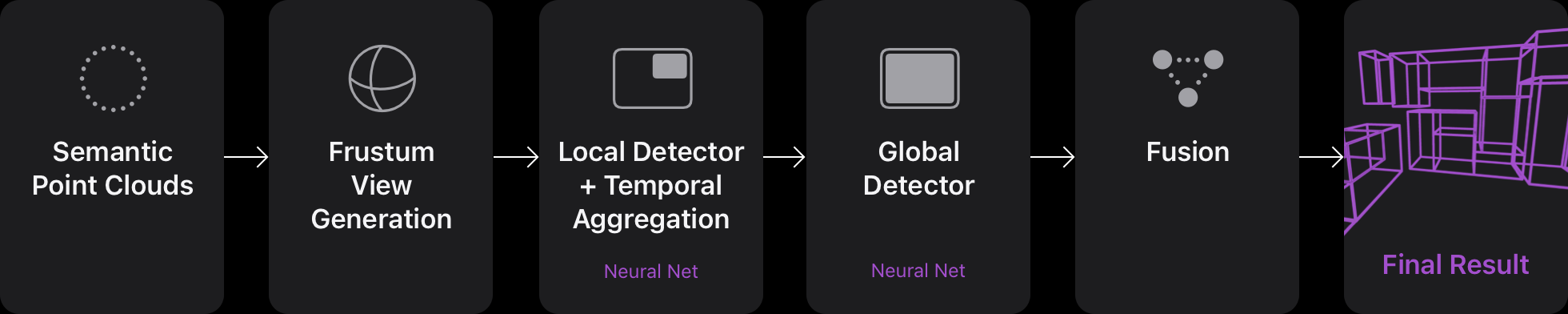
The making of an L-shaped sofa is an example of a relationship between objects during the fusion step. Also, if the object is not intersecting with any wall, then the correlation is calculated by aligning it with the closest one.
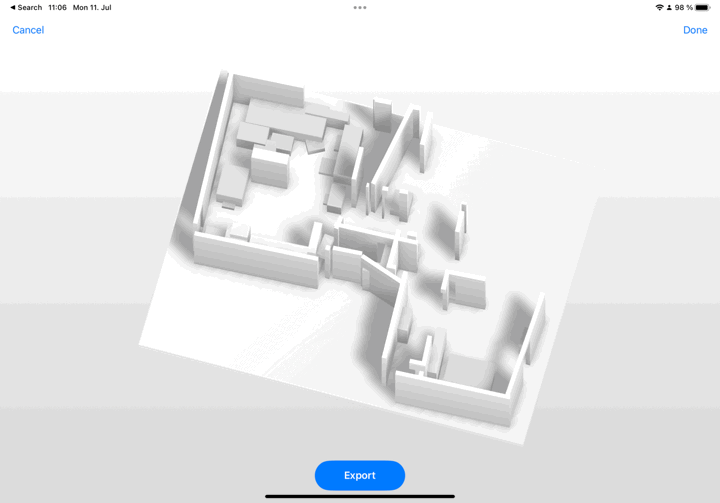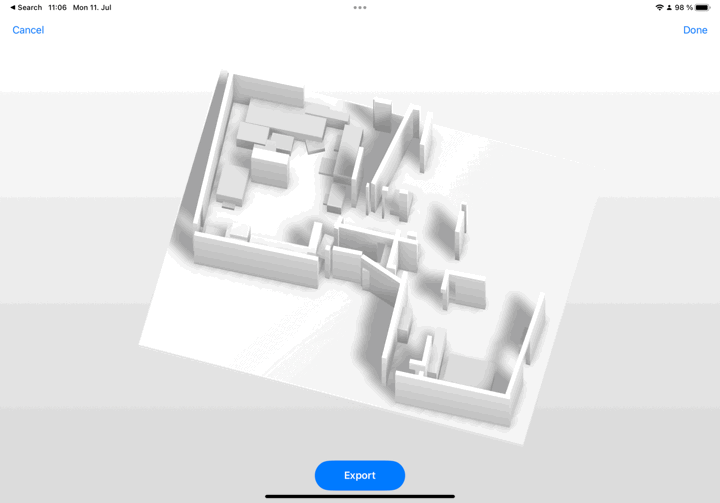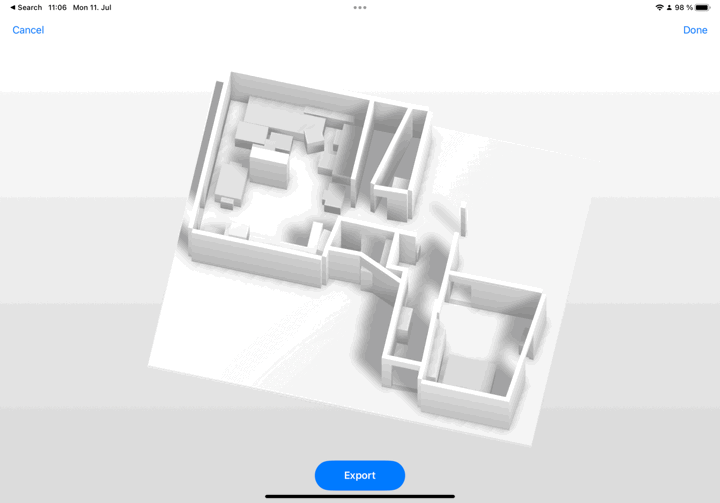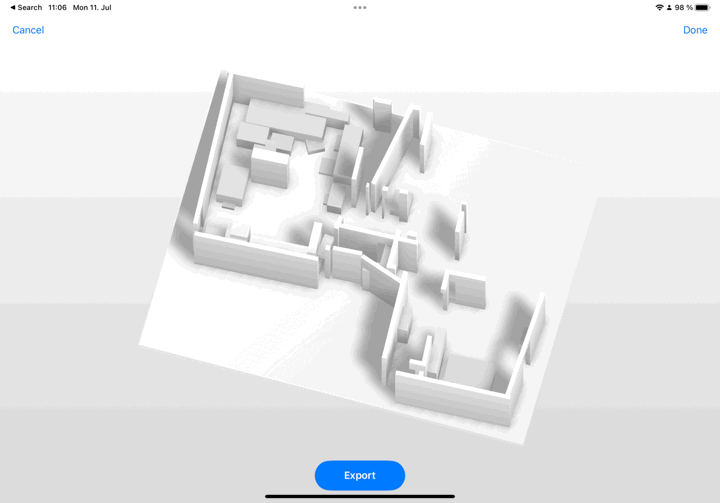
🪴🪑📦 The chair’s category seems to be the most difficult to identify (83% precision) due to heavy occlusion or crowded arrangements.